Principal Coordinate Analysis#
Introduction#
In this notebook we will perform Principal Coordinate Analysis to identify patterns of geographic and genetic structure within the Pf8 dataset.
This notebook should take approximately 50 minutes to run
Principal Coordinate Analysis - PCoA#
PCoA falls into a category of analyses which focus on “dimensionality reduction”. Dimensionality reduction is used in data analysis to simplify complex data by reducing the number of variables while still retaining meaningful properties from the original dataset.
The PCoA we will calculate is based on a large distance matrix of pairwise genetic distances between 24,409 Plasmodium falciparum samples. The distances were generated using high-quality, bi-allelic coding single nucleotide polymorphisms (SNPs) from throughout the Pf genome.
The PCoA seeks to represent these pairwise distances in a lower-dimensional space, while preserving their relative distances as accurately as possible.
Thus, we can simply view relative genetic distances between samples from different geographical locations.
Setup#
Install the MalariaGEN data package:
!pip install malariagen_data -q --no-warn-conflicts
Installing build dependencies ... ?25l?25hdone
Getting requirements to build wheel ... ?25l?25hdone
Preparing metadata (pyproject.toml) ... ?25l?25hdone
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 4.0/4.0 MB 31.1 MB/s eta 0:00:00
?25h Preparing metadata (setup.py) ... ?25l?25hdone
Preparing metadata (setup.py) ... ?25l?25hdone
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 71.7/71.7 kB 5.2 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 765.4/765.4 kB 40.2 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 24.4/24.4 MB 2.3 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8.1/8.1 MB 6.8 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 210.7/210.7 kB 14.2 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 6.3/6.3 MB 3.9 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3.2/3.2 MB 52.7 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.8/7.8 MB 85.1 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.0/1.0 MB 47.3 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 77.8/77.8 kB 5.9 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 101.7/101.7 kB 7.2 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8.6/8.6 MB 87.6 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 228.0/228.0 kB 15.9 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 43.3/43.3 kB 3.2 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 13.3/13.3 MB 83.5 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.6/1.6 MB 61.0 MB/s eta 0:00:00
?25h Building wheel for malariagen_data (pyproject.toml) ... ?25l?25hdone
Building wheel for dash-cytoscape (setup.py) ... ?25l?25hdone
Building wheel for asciitree (setup.py) ... ?25l?25hdone
Install another required packages, scikit-bio and s3fs:
!pip install -q --no-warn-conflicts scikit-bio s3fs
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.7/2.7 MB 24.8 MB/s eta 0:00:0000:0100:01
?25h Installing build dependencies ... ?25l?25hdone
Getting requirements to build wheel ... ?25l?25hdone
Preparing metadata (pyproject.toml) ... ?25l?25hdone
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 11.7/11.7 MB 79.3 MB/s eta 0:00:00
?25h
Load the required Python libraries:
import malariagen_data
import s3fs
from botocore.config import Config
from ftplib import FTP
import scipy.stats
import scipy.spatial.distance
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import collections
from skbio.stats.ordination import pcoa
from google.colab import drive
Data Access#
First load the Pf8 metadata:
## Load Pf8 data
release_data = malariagen_data.Pf8()
sample_metadata = release_data.sample_metadata()
sample_metadata.head(3) # View the data
# Notice we have data for all 33,325 samples
sample_metadata.shape
(33325, 17)
We then need to load the distance matrix, which is available from Sanger’s cloud storage.
# Cloud path to Pf8 distance matrix
s3_path = "s3://pf8-release/Pf8_mean_genotype_distance.npy"
config = {'signature_version': 's3',
's3': { 'addressing_style': 'virtual' }
}
fs = s3fs.S3FileSystem(
anon=True,
endpoint_url='https://cog.sanger.ac.uk',
config_kwargs=config
)
# Open and load the .npy file
with fs.open(s3_path, 'rb') as f:
mean_distance_matrix = np.load(f)
print('Distance matrix loaded successfully.')
Subset data#
We want to make sure we can rely on our results. To give the best chance of this, we select only samples which passed quality control (QC) filters.
We need to subset the sample_metadata dataframe and the distance matrix so they only contain these samples.
# Subset the metadata using the 'QC pass' column
# Select only rows where the value is 'True'
sample_metadata_qc_pass = sample_metadata[sample_metadata['QC pass'] == True]
sample_metadata_qc_pass.shape
We now have 24,409 samples in this dataframe.
# Subset the distance matrix using the same column
mean_distance_matrix_qc_pass = mean_distance_matrix[sample_metadata['QC pass'].values][:, sample_metadata['QC pass'].values]
mean_distance_matrix_qc_pass.shape
(24409, 24409)
And we have 24,409 samples in the distance matrix.
To save space and stay within the Colab notebook’s memory limit, we must empty the distance matrix that includes non-QC values.
mean_distance_matrix = None
Perform PCoA#
Now we will perform the dimensionality reduction to pull out the most important components of variation in the dataset.
# The diagonal of the matrix, where each sample is compared to itself,
# must be manually set to zero to avoid an error from pcoa
np.fill_diagonal(mean_distance_matrix_qc_pass, 0)
Note: The following cell may take 45 minutes to complete while the Colab is up and running.
We may see a warning message about negative eigenvalues. These values are small in magnitude, so please ignore the message.
# This will produce the underlying values for the figure
pcoa_results = pcoa(mean_distance_matrix_qc_pass)
/usr/local/lib/python3.10/dist-packages/skbio/stats/ordination/_principal_coordinate_analysis.py:146: RuntimeWarning: The result contains negative eigenvalues. Please compare their magnitude with the magnitude of some of the largest positive eigenvalues. If the negative ones are smaller, it's probably safe to ignore them, but if they are large in magnitude, the results won't be useful. See the Notes section for more details. The smallest eigenvalue is -0.0007589793531224132 and the largest is 0.003880083793774247.
warn(
# Make sure the results are the size we expect (24,409)
pcoa_results.samples.shape
(24409, 24409)
pcoa_results.samples
| PC1 | PC2 | PC3 | PC4 | PC5 | PC6 | PC7 | PC8 | PC9 | PC10 | ... | PC24400 | PC24401 | PC24402 | PC24403 | PC24404 | PC24405 | PC24406 | PC24407 | PC24408 | PC24409 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.000366 | 0.000005 | -0.000095 | 4.664460e-05 | -0.000038 | 0.000012 | -0.000008 | 0.000025 | 3.314548e-05 | -1.353946e-07 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | -0.000367 | -0.000035 | -0.000131 | 5.729959e-05 | 0.000017 | -0.000019 | -0.000092 | 0.000085 | -4.657099e-05 | 4.012898e-05 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | -0.000281 | 0.000003 | 0.000048 | 2.021483e-05 | -0.000003 | -0.000004 | -0.000041 | -0.000026 | -3.138813e-05 | -1.981967e-05 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | -0.000302 | -0.000018 | -0.000012 | 4.239124e-06 | 0.000019 | -0.000014 | -0.000005 | -0.000011 | -4.058877e-05 | -4.042525e-05 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | -0.000347 | -0.000020 | -0.000069 | -6.216652e-05 | 0.000047 | -0.000006 | -0.000077 | 0.000066 | -3.696777e-05 | -2.735753e-06 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 24404 | -0.000243 | 0.000015 | -0.000052 | 7.995157e-06 | 0.000046 | 0.000001 | 0.000073 | -0.000047 | -2.684649e-05 | 2.814960e-06 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 24405 | -0.000319 | -0.000059 | -0.000057 | 5.662256e-06 | 0.000009 | -0.000022 | 0.000041 | -0.000011 | -9.411604e-07 | 7.857020e-06 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 24406 | -0.000274 | -0.000003 | -0.000037 | 4.314590e-06 | 0.000027 | 0.000005 | 0.000061 | -0.000010 | -5.066524e-05 | 5.229774e-06 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 24407 | -0.000265 | 0.000012 | -0.000034 | -9.872398e-07 | 0.000051 | 0.000002 | -0.000002 | 0.000006 | -6.517883e-05 | -2.840834e-05 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 24408 | -0.000344 | -0.000043 | -0.000076 | 6.315483e-05 | 0.000011 | -0.000027 | -0.000096 | 0.000099 | -1.382476e-05 | 5.280112e-05 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
24409 rows × 24409 columns
Now dimensionality reduction has been applied, we are given a list of Principal Coordinates (PC) and information on the proportion of total data variation explained by each PC.
# View proportion of variation explained by each PC
pcoa_results.proportion_explained*100
| 0 | |
|---|---|
| PC1 | 15.324158 |
| PC2 | 2.223303 |
| PC3 | 0.841966 |
| PC4 | 0.668389 |
| PC5 | 0.585150 |
| ... | ... |
| PC24405 | 0.000000 |
| PC24406 | 0.000000 |
| PC24407 | 0.000000 |
| PC24408 | 0.000000 |
| PC24409 | 0.000000 |
24409 rows × 1 columns
0.004103*100
0.4103
The most useful PCs for explaining sample similarity/dissimilarity are those which explain most of the variation
You can see that the 1st PC, PC1, explains the most variation, at around 15.3% of the total variation.
PC2 explains 2.2x less variation, at around 2%.
PC3 explains even less, at 0.8%.
Eventually the PCs become useless, explaining 0% of variation.
# View a preliminary PCoA plot from these results
# This plot shows sample relatedness along three PCs: PC1,PC2,PC3
pcoa_results

It looks like there might be distinct clusters of samples emerging along the first three PCs. At the moment, we can’t say more than that because we have not assigned any information to the points (samples) in the plot.
We want to know whether samples show geographical genetic structure, so we need to give each major sub-population a distinguishing factor. In this case, we will use different colours for each sub-population.
Assign colours to sub-populations#
# View subpopulations in dataset
sample_metadata_qc_pass['Population'].value_counts()
| count | |
|---|---|
| Population | |
| AF-W | 8914 |
| AS-SE-E | 5880 |
| AF-E | 4173 |
| AS-SE-W | 1888 |
| AS-S-FE | 1377 |
| AF-C | 1212 |
| OC-NG | 341 |
| SA | 227 |
| AF-NE | 209 |
| AS-S-E | 188 |
We will use an ordered dictionary to assign colours (designated with a HEX code) to major sub-populations.
Use of an ordered dictionary, rather than a regular dictionary, allows us to keep sub-populations in order from west to east.
# Define ordered dictionary to map colours to sub-populations
colourings = collections.OrderedDict()
colourings['Population'] = collections.OrderedDict()
# We nest a regular dictionary within the ordered dictionary which contains the
# colour-subpopulation associations
population_colours = {}
population_colours['SA'] = "#4daf4a"
population_colours['AF-W']= "#e31a1c"
population_colours['AF-C'] = "#fd8d3c"
population_colours['AF-NE'] = "#bb8129"
population_colours['AF-E'] = "#fecc5c"
population_colours['AS-S-E'] = "#dfc0eb"
population_colours['AS-S-FE'] = "#984ea3"
population_colours['AS-SE-W'] = "#9ecae1"
population_colours['AS-SE-E'] = "#3182bd"
population_colours['OC-NG'] = "#f781bf"
# Assign the population_colours dictionary to the 'Population' key within the colourings ordered dictionary.
colourings['Population'] = population_colours
# Check all associations are as expected
colourings['Population']
{'SA': '#4daf4a',
'AF-W': '#e31a1c',
'AF-C': '#fd8d3c',
'AF-NE': '#bb8129',
'AF-E': '#fecc5c',
'AS-S-E': '#dfc0eb',
'AS-S-FE': '#984ea3',
'AS-SE-W': '#9ecae1',
'AS-SE-E': '#3182bd',
'OC-NG': '#f781bf'}
Plot the PCoA#
We will define two functions that will build the PCoA plot:
1. plot_pca_coords: This function takes the pcoa results and the sample metadata as input, while also having several other parameters to customise the plot appearance.
An important parameter to note is sample_populations. The ordering of populations in the plot determines the order that points are layered on the plot. So if Central Africa is plotted before the larger, closely related populations of West Africa and East Africa, then Central Africa becomes covered by the larger populations’ points. This parameter lets us tweak the order of populations so that plot clarity is enhanced.
# Define the function and its input parameters
def plot_pca_coords(pcoa_results, pc1, pc2, ax, df_samples=sample_metadata_qc_pass,
sample_populations=None,
population_column='Population',
xlim=None, ylim=None,
include_n_in_legend=False,
include_prop_explain=False,
is_label_sample=False,
legend_loc=None,
bbox_to_anchor=None,
is_randomize=False,
legend_order=None
):
# A note on ordering populations
"""
Parameters:
- sample_populations: array-like (str)
populations to display.
If target_populations is None, then displays all populations in the order they appear
in the df_samples DataFrame
- legend_order: array-like (str)
order of populations in the legend. If None, and sample_populations is None,
then uses the order they appear in df_samples.
If None and sample_populations is filled, then uses the order in sample_populations.
"""
# Remove the upper and right-hand borders from the plot to ensure points are not obscured
sns.despine(ax=ax, offset=5)
# Determine which population ordering to use
if sample_populations is None:
target_populations = df_samples[population_column].unique()
else:
target_populations = sample_populations
# This condition deals with randomising the plotting of population points
# If the parameter is set to 'True' then points are plotted randomly
# If it is set to 'False' then populations are plotted in order.
if is_randomize:
# Filter samples according to the target populations
df_samples_filt = df_samples.loc[df_samples[population_column].isin(target_populations),
[population_column]].copy()
# Select and apply their corresponding subpopulation colour
colourings_df = pd.DataFrame.from_dict(colourings[population_column], orient="index", columns=["color"])
colourings_df.index.rename(population_column, inplace=True)
colourings_df = colourings_df.reset_index(drop=False)
df_samples_filt = df_samples_filt.merge(colourings_df, how="left",
left_on=population_column,
right_on=population_column)
# Select corresponding values from pcoa results
filt = np.isin(df_samples[population_column].values, target_populations)
x_filt = pcoa_results.samples.loc[filt, pc1]
y_filt = pcoa_results.samples.loc[filt, pc2]
color = df_samples_filt["color"].values
# Randomly reorder the data points using a permutation of indices.
plot_idx = np.random.permutation(df_samples_filt.shape[0])
x_filt = x_filt[plot_idx]
y_filt = y_filt[plot_idx]
color = color[plot_idx]
# Finally, scatter plot the randomized data points onto the plot
ax.scatter(
x_filt,
y_filt,
marker='o',
color=color,
s=30,
edgecolor='k',
linewidths=.5,
)
else:
# Plot each population in order
for target_popn in target_populations:
x_filt = pcoa_results.samples.loc[df_samples[population_column].values == target_popn, pc1]
y_filt = pcoa_results.samples.loc[df_samples[population_column].values == target_popn, pc2]
color = colourings[population_column][target_popn]
ax.scatter(
x_filt,
y_filt,
marker='o',
color=color,
s=30,
edgecolor='k',
linewidths=.5,
)
# Code for creating the legend
# Generate empty lists to receive data
# These will form key components of the legend
handles = []
labels = []
target_legend_order = legend_order
# If `legend_order` is set to "None", write legend in same order as `target_populations`
if target_legend_order is None:
target_legend_order = target_populuations
for target_pop in target_legend_order:
# Generate a coloured marker to link population names to point colours on the plot
# The marker has a circular shape ('o'),
# a black edge ('mec="k"'), and a color from the population colourings dictionary.
handle = plt.Line2D([], [],
linestyle='none',
marker='o',
mec="k",
markerfacecolor=colourings[population_column][target_pop])
handles.append(handle) # add to handles list
# An option to include population size within the legend text
# Otherwise, just write the population name
if include_n_in_legend:
label = f"{target_pop} (n={df_samples.loc[population_column == target_pop].shape[0]})"
else:
label = target_pop
labels.append(label)
# Define the legend using handles, labels, 'loc' where to place in the plot,
# and bbox_to_anchor which sets the position of the legend box border
ax.legend(handles=handles,
labels=labels,
loc=legend_loc, bbox_to_anchor=bbox_to_anchor)
# An option for labelling individual points on the plot with their sample ID
if is_label_sample:
for i, sample_label in enumerate(df_samples[plot_idx]["Sample"]):
ax.annotate(sample_label, (x_filt[i], y_filt[i]))
# Option to include the proportion of variance explained by each PC
if include_prop_explain:
ax.set_xlabel('%s (%.1f%%)' % (pc1, pcoa_results.proportion_explained[pc1]*100))
ax.set_ylabel('%s (%.1f%%)' % (pc2, pcoa_results.proportion_explained[pc2]*100))
# Otherwise, just use PC values
else:
ax.set_xlabel(pc1)
ax.set_ylabel(pc2)
# Deal with x and y axis limits
if xlim is not None:
ax.set_xlim(xlim)
if ylim is not None:
ax.set_ylim(ylim)
2. fig_pca: This function contains the plot_pca_coords function defined in the previous code block.
In addtion to the funtionality of plot_pca_coords, this function contains specifications for the plot font size, whether to plot multiple subplots, and the possibility of adding a title.
# Define the function and its input parameters
def fig_pca(pcoa_results, pc1=0, pc2=1,
title=None,
df_samples=sample_metadata_qc_pass,
sample_populations=None,
population_column='Population',
figsize=(7, 7),
legend_loc=None,
xlim=None,
ylim=None,
include_n_in_legend=False,
xtick_stepsize=0.001,
bbox_to_anchor=None,
is_label_sample=False,
is_randomize=False,
legend_order=None,
include_prop_explain=False):
# Specify the size of the plot font
rcParams = plt.rcParams
rcParams['font.size'] = 14
rcParams['axes.labelsize'] = 14
# Specify the size of the axes tick label sizes
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
# If no population order is specified, just plot populations
# in the same order as df_samples
if sample_populations is None:
sample_populations = df_samples[population_column].unique()
# Plot coords for two PCs
# This part contains the previously defined function plot_pca_coords
fig = plt.figure(figsize=figsize)
ax = fig.add_subplot(1, 1, 1)
plot_pca_coords(pcoa_results,
pc1, pc2,
ax=ax,
df_samples=df_samples,
sample_populations=sample_populations,
population_column=population_column,
xlim=xlim,
ylim=ylim,
include_n_in_legend=include_n_in_legend,
is_label_sample=is_label_sample,
legend_loc=legend_loc,
bbox_to_anchor=bbox_to_anchor,
is_randomize=is_randomize,
legend_order=legend_order,
include_prop_explain=include_prop_explain)
# Setting a title
if title is not None:
fig.suptitle(title, y=1.02)
# Customise the x-axis tick marks
# Ensure tick marks are spaced appropriately to the current x-axis range
if xtick_stepsize is not None:
start, end = ax.get_xlim()
ax.xaxis.set_ticks(np.arange(np.ceil(start / xtick_stepsize) * xtick_stepsize, end, xtick_stepsize))
# Set a tight_layout() to ensure subplots fit within the figure's boundaries
# without overlapping or getting cut off
fig.tight_layout()
# Return the final PCoA figure
return(fig)
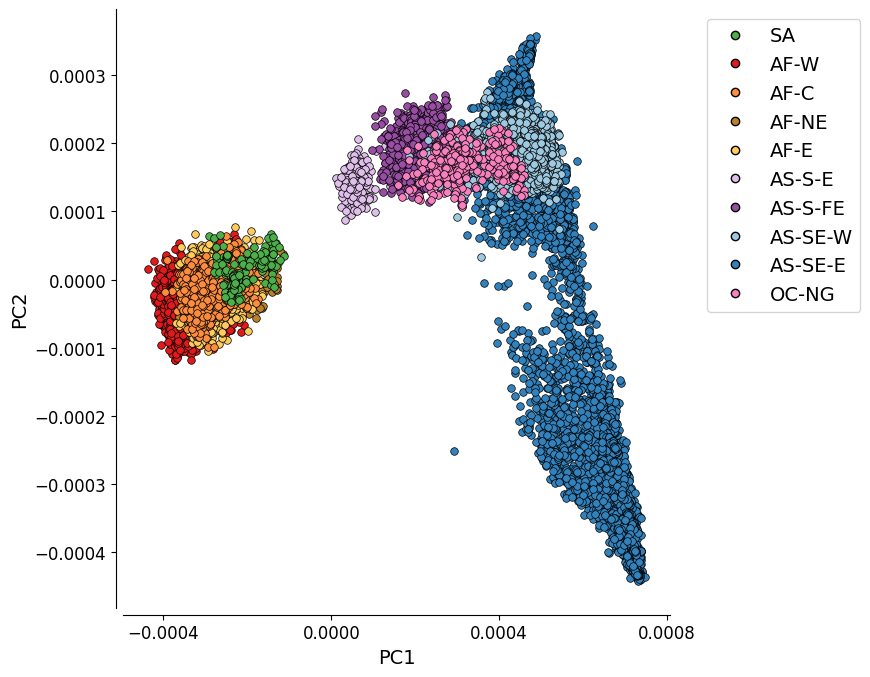
PC1 vs. PC2#
This plot represents the first two components of a genome-wide principal coordinate analysis. The first axis (PC1, 15.3% of variance explained) captures the separation of African and South American from Asian and Oceanian samples. The second axis (PC2, 2.2% of variance explained) captures finer levels of population structure particularly in the eastern SE Asia population.
fig = fig_pca(
pcoa_results,
'PC1', 'PC2',
None,
sample_metadata_qc_pass,
sample_populations=["AF-W", "AF-NE", "AF-E", "AF-C", "SA",
"AS-SE-E", "AS-S-E", "AS-S-FE",
"AS-SE-W", "OC-NG"],
population_column='Population',
figsize=(9, 7),
legend_loc="best",
xtick_stepsize=4e-4,
bbox_to_anchor=(1.05, 1),
is_randomize=False,
legend_order=list(colourings["Population"].keys())
)
Save the figure:
# Mount Google Drive
drive.mount('/content/drive')
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
# Save PCoA plot
# This will send the file to your Google Drive, where you can download it from if needed
# Change the file path if you wish to send the file to a specific location
# Change the file name if you wish to call it something else
file_path = '/content/drive/My Drive/'
file_name = 'PCoA_1_vs_2'
# We save as both .png and .PDF files
fig.savefig(f'{file_path}{file_name}.png', dpi=240, bbox_inches="tight")
fig.savefig(f'{file_path}{file_name}.pdf')
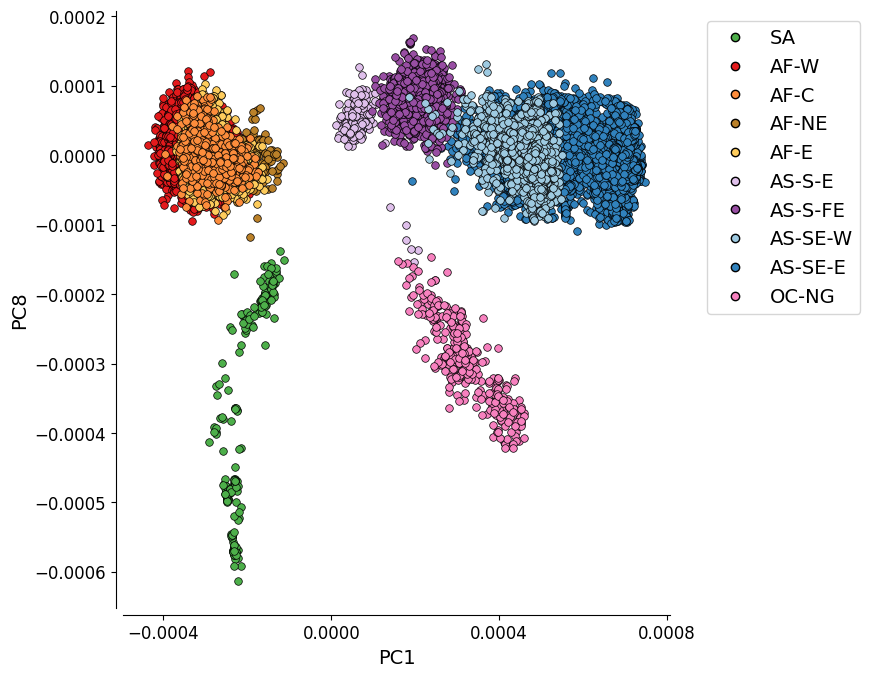
PC1 vs. PC8#
This plot shows the first and eighth components of the genome-wide principal coordinate analysis. It depicts the genetic differentiation between the 10 global subpopulations.
fig = fig_pca(
pcoa_results,
'PC1', 'PC8',
None,
sample_metadata_qc_pass,
sample_populations=["AF-W", "AF-NE", "AF-E", "AF-C", "SA",
"AS-SE-E", "AS-S-E", "AS-S-FE",
"AS-SE-W", "OC-NG"],
population_column='Population',
figsize=(9, 7),
legend_loc="best",
xtick_stepsize=4e-4,
bbox_to_anchor=(1.05, 1),
legend_order=list(colourings["Population"].keys()),
include_prop_explain=False
)
Save the figure:
# Save PCoA plot
# This will send the file to your Google Drive, where you can download it from if needed
# Change the file path if you wish to send the file to a specific location
# Change the file name if you wish to call it something else
file_path = '/content/drive/My Drive/'
file_name = 'PCoA_1_vs_8'
# We save as both .png and .PDF files
fig.savefig(f'{file_path}{file_name}.png', dpi=240, bbox_inches="tight")
fig.savefig(f'{file_path}{file_name}.pdf')
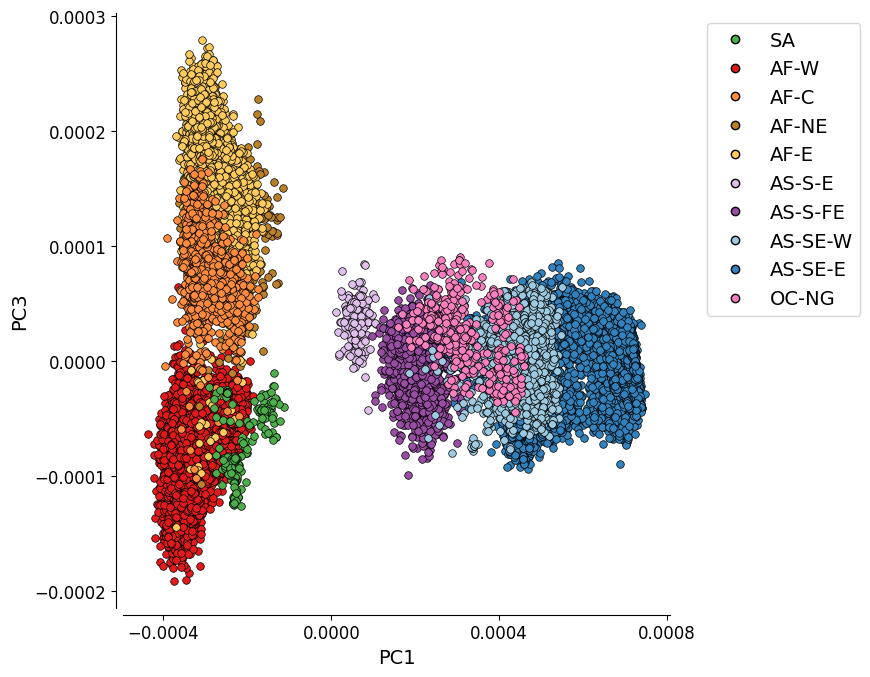
Additional Plot 1: PC1 vs. PC3#
For completeness, we can also look at the PCoA when the PCs which explain most variation are plotted. Here we see PC1 vs PC3, the plot shows the four African populations as looking quite distinct from each other, with there being something of a separation between AF-W and the other three.
fig = fig_pca(
pcoa_results,
'PC1', 'PC3',
None,
sample_metadata_qc_pass,
sample_populations=["AF-W", "AF-NE", "AF-E", "AF-C", "SA",
"AS-SE-E", "AS-S-E", "AS-S-FE",
"AS-SE-W", "OC-NG"],
population_column='Population',
figsize=(9, 7),
legend_loc="best",
xtick_stepsize=4e-4,
bbox_to_anchor=(1.05, 1),
legend_order=list(colourings["Population"].keys())
)
Save the figure:
# Save PCoA plot
# This will send the file to your Google Drive, where you can download it from if needed
# Change the file path if you wish to send the file to a specific location
# Change the file name if you wish to call it something else
file_path = '/content/drive/My Drive/'
file_name = 'PCoA_1_vs_3'
# We save as both .png and .PDF files
fig.savefig(f'{file_path}{file_name}.png', dpi=240, bbox_inches="tight")
fig.savefig(f'{file_path}{file_name}.pdf')
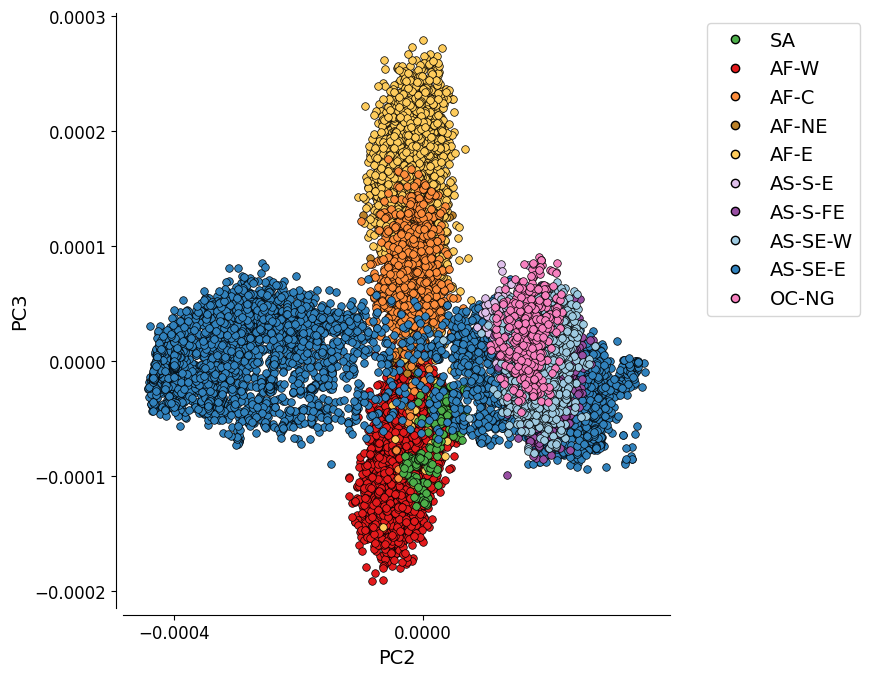
Additional Plot 2: PC2 vs. PC3#
As the variation explained by PC2 (2.2%) and PC3 (0.8%) is not much, the separation between the Asian populations gets less distinct.
fig = fig_pca(
pcoa_results,
'PC2', 'PC3',
None,
sample_metadata_qc_pass,
sample_populations=["AF-W", "AF-NE", "AF-E", "AF-C", "SA",
"AS-SE-E", "AS-S-E", "AS-S-FE",
"AS-SE-W", "OC-NG"],
population_column='Population',
figsize=(9, 7),
legend_loc="best",
xtick_stepsize=4e-4,
bbox_to_anchor=(1.05, 1),
legend_order=list(colourings["Population"].keys())
)
#fig.savefig('figures/PCoA_2_vs_3.pdf')
#fig.savefig('figures/PCoA_2_vs_3.png', dpi=600)
Save the figure:
# Save PCoA plot
# This will send the file to your Google Drive, where you can download it from if needed
# Change the file path if you wish to send the file to a specific location
# Change the file name if you wish to call it something else
file_path = '/content/drive/My Drive/'
file_name = 'PCoA_2_vs_3'
# We save as both .png and .PDF files
fig.savefig(f'{file_path}{file_name}.png', dpi=240, bbox_inches="tight")
fig.savefig(f'{file_path}{file_name}.pdf')
Notebook Complete!